Hello Community ![]()
Part 2 of the journey into synthetic data generation is here.
Having so many brilliant models available is great, but sometimes you have to choose an option (not necessarily the latest or the most popular) that best fits your use case!
While you could rely on benchmarks (![]() Did you know
Did you know ![]() has its own, which we call Leaderboards), not all domains are taken into account.
has its own, which we call Leaderboards), not all domains are taken into account.
We have just the tool for you! Inspired by the principles in my first post, I will perform local inferencing via Ollama and send the inference to Labelbox so that it can be evaluated by humans!
This time, I selected DeepSeek r1 and chose Mistral as a challenger ![]() and sent a few prompts related to the following topic: Fraud detection in financial services
and sent a few prompts related to the following topic: Fraud detection in financial services ![]()
Requirements
In this guide this what you will need to follow along
- Ollama
- deepseek-r1 via Ollama (I used the 8B version)
- Mistral-small via Ollama (not that’s small 22B version)
- A cloud provider of your choice (I used Azure) to store the files
- An integration to work with your newly created Labelbox offline MMC file
Synthetic data generation script
Code to generate the inference locally
import json
import os
import time
from typing import List, Dict, Any, Optional, Tuple
from azure.storage.blob import BlobServiceClient
import subprocess
from tqdm import tqdm
import re
import uuid
class OllamaTopicGenerator:
def __init__(self,
model1: str = 'deepseek-r1:8b',
model2: str = 'mistral-small:22b',
topics: Optional[List[str]] = None,
connect_str: Optional[str] = None,
container_name: Optional[str] = None):
"""
Initialize the topic generator with two different models.
Args:
model1: First Ollama model to use
model2: Second Ollama model to use
topics: List of topics/prompts to explore
connect_str: Azure Storage connection string
container_name: Azure Storage container name
"""
self.model1 = model1
self.model2 = model2
self.topics = topics or []
# Azure Storage setup
self.connect_str = connect_str
self.container_name = container_name
self.blob_service_client = None
self.container_client = None
if connect_str and container_name:
self._initialize_azure_clients()
def _initialize_azure_clients(self) -> None:
"""Initialize Azure Storage clients."""
try:
self.blob_service_client = BlobServiceClient.from_connection_string(self.connect_str)
self.container_client = self.blob_service_client.get_container_client(self.container_name)
except Exception as e:
print(f"Error initializing Azure clients: {e}")
self.blob_service_client = None
self.container_client = None
def generate_model_response(self, topic: str, model: str) -> Tuple[Optional[str], Optional[float]]:
"""
Generate a response for a specific topic using the specified Ollama model.
Args:
topic: Topic/prompt to explore
model: Ollama model to use
Returns:
Tuple of (response text, inference time) or (None, None) if generation fails
"""
try:
start_time = time.time()
result = subprocess.run([
'ollama', 'run',
model,
topic
],
capture_output=True,
text=True,
timeout=180)
if result.returncode != 0:
raise subprocess.CalledProcessError(result.returncode, result.args, result.stdout, result.stderr)
inference_time = round(time.time() - start_time, 2)
return result.stdout.strip(), inference_time
except (subprocess.CalledProcessError, subprocess.TimeoutExpired) as e:
print(f"Error generating response for topic: {topic} with model: {model}")
print(f"Error details: {str(e)}")
return None, None
def generate_topic_response(self, topic: str) -> Optional[Dict[str, Any]]:
"""
Generate responses for a specific topic using both models.
Args:
topic: Topic/prompt to explore
Returns:
Dictionary with topic details and LLM responses, or None if generation fails
"""
# Generate response from model1
response1, inference_time1 = self.generate_model_response(topic, self.model1)
if response1 is None:
return None
# Generate response from model2
response2, inference_time2 = self.generate_model_response(topic, self.model2)
if response2 is None:
return None
return {
'topic': topic,
'model1': {
'name': self.model1,
'response': response1,
'inference_time': inference_time1
},
'model2': {
'name': self.model2,
'response': response2,
'inference_time': inference_time2
}
}
def generate_dataset(self) -> List[Dict[str, Any]]:
"""
Generate responses for all topics using both models.
Returns:
List of topic responses
"""
dataset = []
for topic in tqdm(self.topics, desc=f"Exploring Topics with {self.model1} and {self.model2}"):
if response := self.generate_topic_response(topic):
dataset.append(response)
return dataset
def upload_to_azure(self, data: str, blob_name: str) -> bool:
"""
Upload data to Azure Blob Storage.
Args:
data: Data to upload
blob_name: Name of the blob
Returns:
True if successful, False otherwise
"""
if not (self.blob_service_client and self.container_client):
print("Azure Storage clients not properly initialized")
return False
try:
data_bytes = data.encode('utf-8')
blob_client = self.container_client.get_blob_client(blob_name)
blob_client.upload_blob(data_bytes, overwrite=True)
print(f"Uploaded to Azure: {blob_name}")
return True
except Exception as e:
print(f"Error uploading to Azure: {e}")
return False
def generate_labelbox_json(self, dataset: List[Dict[str, Any]], save_locally: bool = False) -> None:
"""
Convert dataset to Labelbox JSON format and save to Azure and/or locally.
Args:
dataset: List of generated topic responses
save_locally: Whether to also save files locally
"""
for data in dataset:
filename = self._sanitize_filename(data['topic']) + '.json'
# Generate unique IDs for each message
user_id = str(uuid.uuid4())
model1_id = str(uuid.uuid4())
model2_id = str(uuid.uuid4())
message_id = str(uuid.uuid4())
response1_id = str(uuid.uuid4())
response2_id = str(uuid.uuid4())
labelbox_json = {
"type": "application/vnd.labelbox.conversational.model-chat-evaluation",
"version": 2,
"actors": {
user_id: {
"role": "human",
"metadata": {"name": "user"}
},
model1_id: {
"role": "model",
"metadata": {
"modelConfigName": data['model1']['name'],
"modelConfigId": str(uuid.uuid4())
}
},
model2_id: {
"role": "model",
"metadata": {
"modelConfigName": data['model2']['name'],
"modelConfigId": str(uuid.uuid4())
}
}
},
"messages": {
message_id: {
"actorId": user_id,
"content": [
{"type": "text", "content": data['topic']}
],
"childMessageIds": [response1_id, response2_id]
},
response1_id: {
"actorId": model1_id,
"content": [
{"type": "text", "content": data['model1']['response']}
],
"childMessageIds": []
},
response2_id: {
"actorId": model2_id,
"content": [
{"type": "text", "content": data['model2']['response']}
],
"childMessageIds": []
}
},
"rootMessageIds": [message_id]
}
json_str = json.dumps(labelbox_json, indent=2, ensure_ascii=False)
if self.blob_service_client and self.container_client:
self.upload_to_azure(json_str, filename)
if save_locally:
os.makedirs('labelbox_outputs', exist_ok=True)
output_path = os.path.join('labelbox_outputs', filename)
with open(output_path, 'w', encoding='utf-8') as f:
f.write(json_str)
print(f"Saved locally: {output_path}")
@staticmethod
def _sanitize_filename(filename: str) -> str:
"""
Convert topic to a valid filename.
Args:
filename: Original filename/topic
Returns:
Sanitized filename
"""
filename = re.sub(r'[<>:"/\\|?*]', '', filename)
filename = filename.replace(' ', '_')[:100].strip('_')
return filename or 'unnamed_topic'
def main():
# Azure Storage configuration
connect_str = os.getenv('connect_str') # Changed to standard env var name
container_name = "synthetic-data-maths"
# Example usage with math topics
fraud_detection_topics = [
"Understanding the challenges of fraud detection in financial services",
"The role of customer education in fraud prevention",
"Legal and regulatory aspects of fraud detection in financial institutions",
"Collaborative approaches to combating fraud in the financial industry",
"Fraud detection in emerging financial technologies",
"The impact of fraud on customer trust and loyalty",
"Developing effective internal controls to mitigate fraud risks",
"The importance of continuous monitoring and reporting",
"Maintaining a balance between fraud prevention and customer experience",
"Future trends and technologies shaping the fraud detection landscape"
]
try:
generator = OllamaTopicGenerator(
model1='deepseek-r1:8b',
model2='mistral-small:22b',
topics=fraud_detection_topics,
connect_str=connect_str,
container_name=container_name
)
topic_responses = generator.generate_dataset()
generator.generate_labelbox_json(topic_responses, save_locally=True) #if you need to want to keep a local copy
except Exception as e:
print(f"Error in main execution: {e}")
if __name__ == '__main__':
main()
Send the data to Labelbox
Then we send the from Azure to Labelbox:
Code to send your Labelbox formated inference file(s) to Azure
import labelbox as lb
from azure.storage.blob import BlobServiceClient, ContainerClient
import os
API_KEY = os.environ.get('LABELBOX')
client = lb.Client(api_key=API_KEY)
# Azure connection string
connect_str = os.environ.get('connect_str')
service = BlobServiceClient.from_connection_string(connect_str)
container_name = 'fraud_detection_topics'
container_client = service.get_container_client(container_name)
#retrieve LB integration
organization = client.get_organization()
iam_integration = organization.get_iam_integrations()[0]
iam_integration.name
dataset = client.create_dataset(name=f"Azure_{container_name}",iam_integration=iam_integration)
blob_list = container_client.list_blobs()
uploads = []
for blob in blob_list:
url = f"{service.url}{container_client.container_name}/{blob.name}"
uploads.append(dict(row_data = url, global_key = blob.name))
task = dataset.create_data_rows(uploads)
task.wait_till_done()
print(task.errors)
Configure the MMC offline in Labelbox
- Go to Labelbox
- Select Multimodal chat

- Choose the Offline chat

You can also follow our documentation to set this up as well as creating batches and the ontology you need.
Here is a look at the editor:
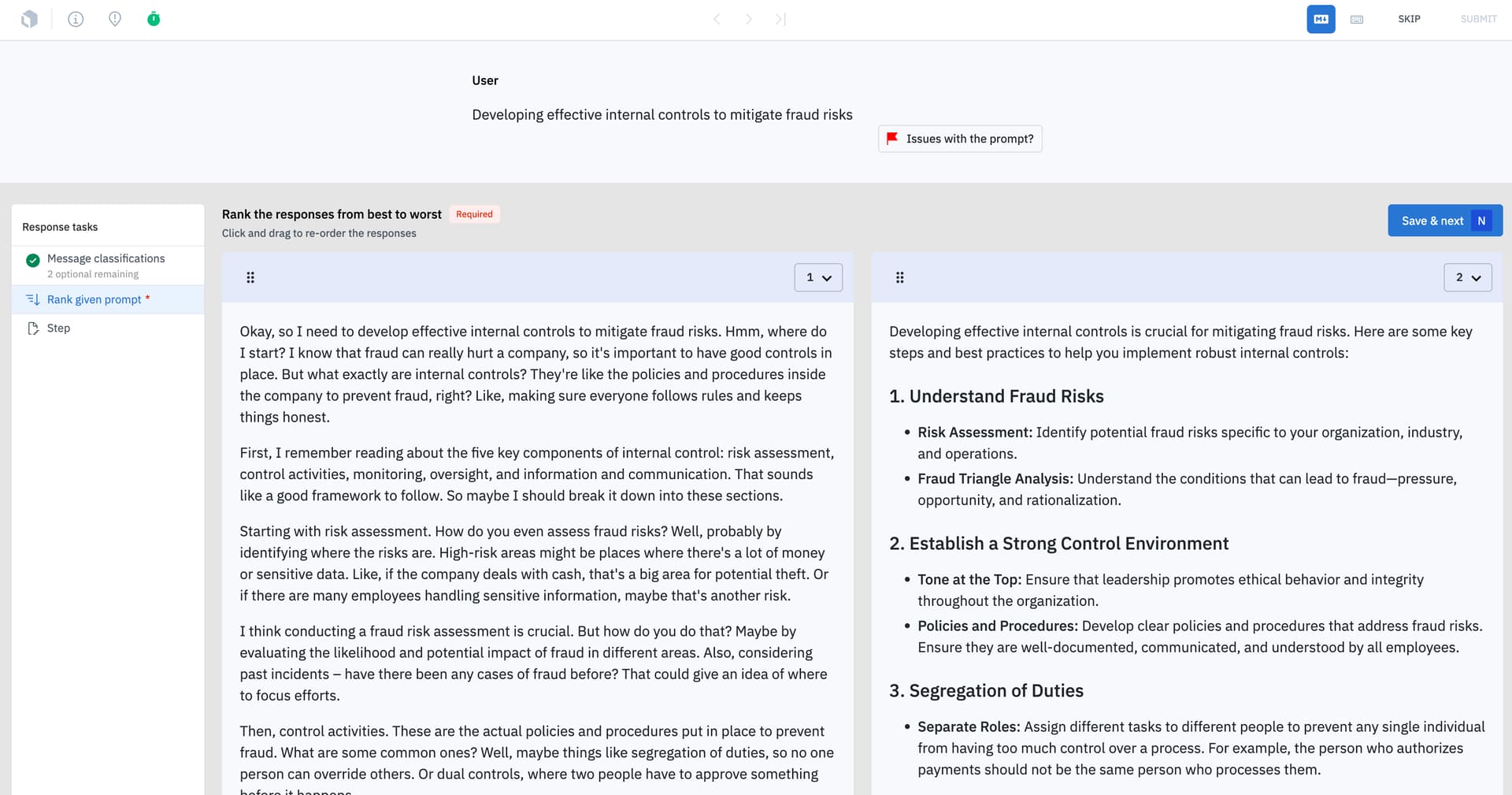
Happy labeling!
Once the human review is done, you will get auto generated stats! (this is for presentation purpose only!)

Part 1 is available: [UPDATED] How to: Generate Synthetic data locally (DeepSeek-R-0528) and curate it in Labelbox